Database Server Scaling Strategies
One of the most difficult tasks for any cloud architect is scaling out the databases required to power a Realscale website.
Until recently, most databases allowed only vertical scaling through the addition of more hardware, or horizontal scaling through techniques such as data replication. While these are still viable options, next generation data stores are offering new techniques for scaling databases.
Next Generation Data Storage
Most organizations utilize a relational database. These databases organize data into tables, with each record captured as a row within each table. Relational databases often adhere to the ACID properties (Atomicity, Consistency, Isolation, Durability). These properties guarantee that database transactions are processed reliably, with one or more operations on the data isolated to a single transaction that will either succeed or fail. This reliability is often desired for many organizations. However, non-relational data stores, often labeled “NoSQL” data stores to reflect their differences to relational databases, have become more popular in recent years and are enabling a new generation of scaling options.
As websites such as Amazon, Facebook, Google, Digg, and Twitter struggled to handle the increased load of their user base, scalable data storage became more important. While many SQL database vendors offer clustering and high availability solutions, many vendors often focused their optimizations around read‐mostly data. This led to difficulties scaling when large amounts of data needed to be written across tens of thousands of requests per second. In addition, SQL vendors often failed to deliver satisfactory results for newer website requirements such as efficient indexing of very large data sets, streaming data, and high traffic sites.
To solve these problems, data storage and access continues to be rethought by considering the exclusion of things such as ACID‐based transactions, relational data, and fixed schemas. Some NoSQL data stores even moved away from schemas completely, focusing on the storage and retrieval of key/value pairs.
Non‐relational data stores are not a new thing. Directory servers, Object Databases, and XML Databases are three popular alternatives prior to the inception of the NoSQL movement in 2009. Each of these data stores offered different styles of capabilities, storage, and performance alternatives to SQL‐based data stores.
Changing the Way Data is Managed
Transactions
Many of the popular NoSQL data stores abandon or constrain transaction support, allowing data to be visible before all updates have been successfully stored. This increases the performance of new or updated records but requires more thought during development to prevent losing user data.
Relational data
Some NoSQL solutions don’t have a concept of relationships between data. This results in the removal of many relational concepts, such as foreign keys and relational constraints. The result is that the data store doesn’t have to check and enforce these rules and therefore increase write performance.
Fixed schemas
Most NoSQL data stores do not require a fixed schema, allowing data storage and retrieval to become faster as values don’t have to be verified against declared data types or required (e.g. NOT NULL) constraints.
Immediate vs. Eventual Consistency
Immediate Consistency is the concept of ensuring that all data accessible from all servers is in a known state. Most SQL data stores provide immediate consistency, meaning that when a piece of data is written, all database servers involved must accept the change and make this change available to anyone else that requests the same data.
Eventual Consistency breaks down this requirement, allowing the local data store executing the change to announce the change to other servers at some point in the future, but return control to the application immediately after the update has been made. Other servers will eventually come into consistency with the first server that received the change, but there is no guarantee of when this will happen.
Data Locking
Traditionally, SQL data stores must lock a particular row in a table when it is to be modified. This prevents multiple application calls from editing the same data at the same time, ensuring safe updates without collisions.Some data stores eliminate row‐level locking, instead opting for versioning and automated merging of data. This speeds up parallel writes and prevent applications from waiting for a lock to be released before it updates the row. It also eliminates the need to add application‐level versioning to prevent data from being improperly updated by parallel update requests. Some data stores push the responsibility of data concurrency management to the application, allowing for consideration based on the specific needs of the application.
Types of Databases
- Relational – stores data into classifications (‘tables’), with each table consisting of one or more records (‘rows’) and identified by a primary key. Tables may be related through their keys, allowing queries to join data from multiple tables together to access any/all required data. Relational databases require fixed schemas on a per-table basis that are enforced for each row in a table.
- Document – Document stores allow for the storage of grouped information with any number of fields that may contain simple or complex values. Each document stored may have different fields, unlike SQL tables that require fixed schemas. Some document stores focus on storing specific types of semi-structured documents, such as XML, JSON, etc. Document stores offer extreme flexibility to developers, as fixed schemas do not need to be developed.
- Key/Value – Key/Value stores offer great simplicity in data storage, allowing for massive scalability of both reads and writes. Values are stored with a unique key (“bob”) and a value (“555-555-1212”) and may be manipulated using the following operations: Add, Reassign (Update), Remove, and Read. Some storage engines offer additional data structure management within these simple operations.
- Graph – Graph stores focus on storing nodes, edges, and properties to build relationships between entities. These stores are very useful in navigating between entities and querying for relationships between them to any depth.
- Search– Search stores are optimized for data querying on one or more fields. Often, search-based data stores allow for data faceting, which allows for multi-dimensional exploration and drill-down capabilities.
Patterns for Scaling Databases
There are a few techniques that enable a database to scale out with more servers and therefore more capacity. Some techniques work better for specific types of databases or for specific vendors. Let’s look at each technique in turn.
Database Scaling Pattern #1: Read Replicas
Read replicas allow data to be available for reading across any number of servers, called “slaves”. One server remains the “master” and accepts any incoming write requests, along with read requests. This technique is common for relational databases, as most vendors support replication of data to multiple read-only servers. The more read replicas installed, the more read-based queries may be scaled.
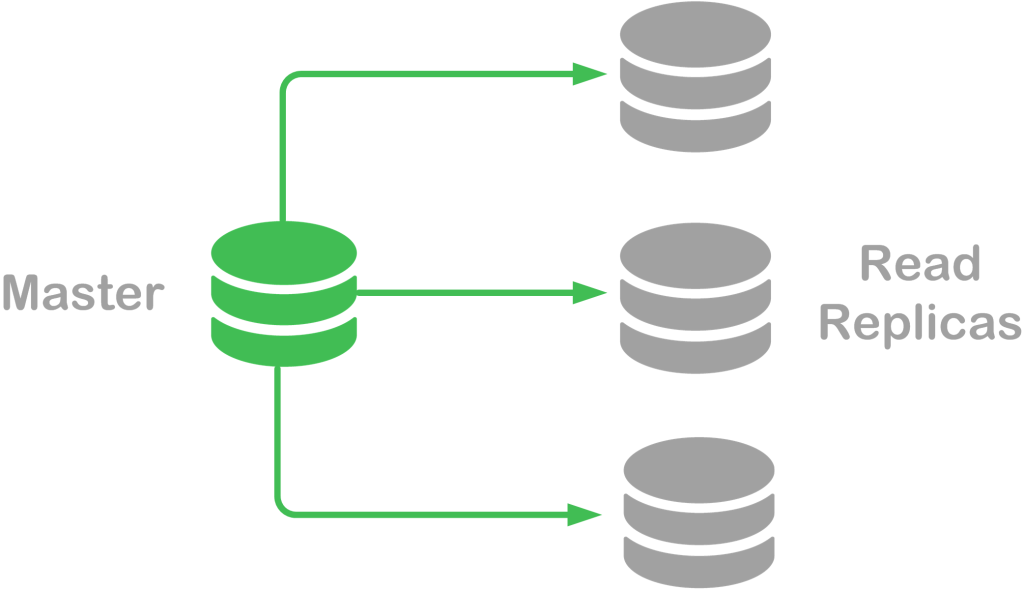
In addition to supporting a greater scale of read-only queries, the read replica strategy is used to offload long-running reports that require long-running queries to dedicated servers and away from typical user traffic. This technique is also used for high availability of the database, since the master read/write server can be replaced by a slave server as it is an exact copy.
To take advantage of the read replica scaling technique, applications must be designed to direct read-based queries to any one of the read replicas, while directing database changes (create, update, delete) to the master server. As you likely noted, this technique works best when you have limited data changes but need to scale out read queries.
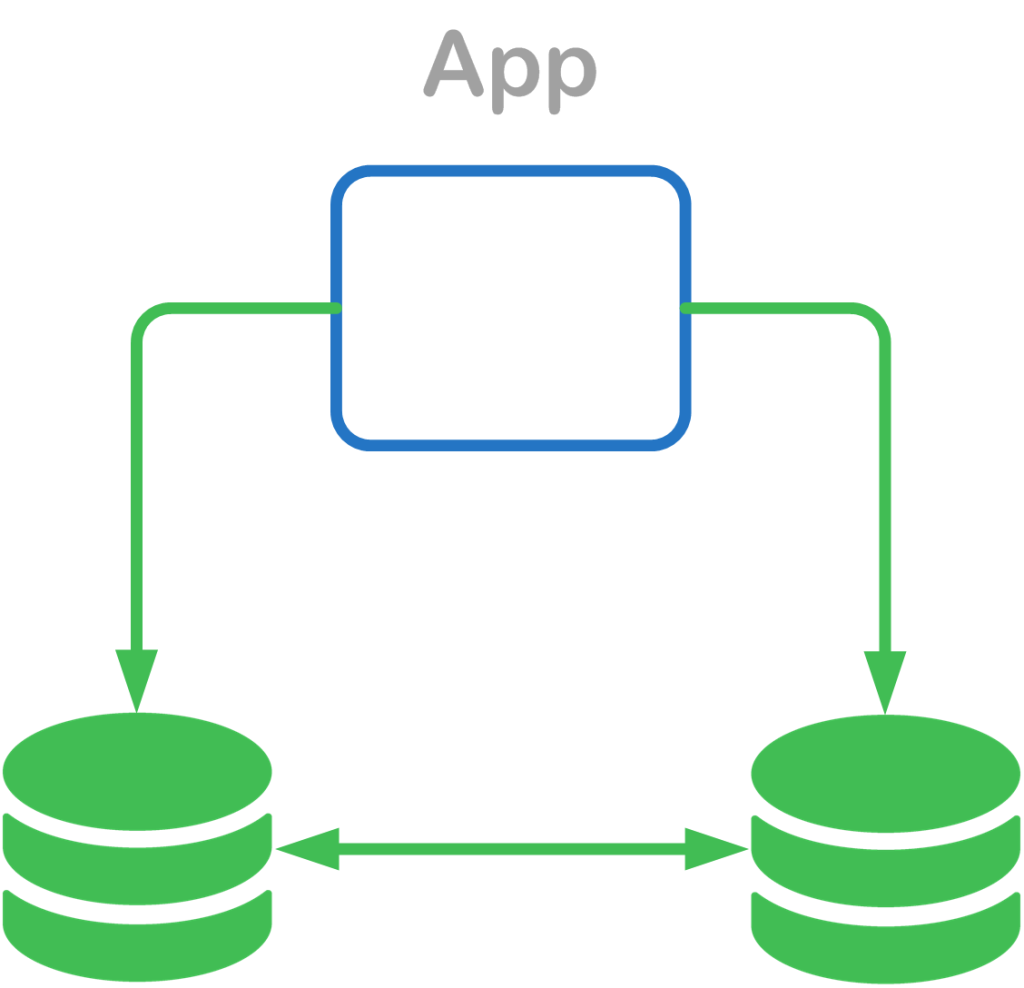
Database Scaling Pattern #2: Multi-Master
While the read replica technique allows for scaling out reads, what happens if you need to scale out to a large number of writes as well? The multi-master technique may be used to allow any client to write data to any database server. This enables all read replicas to be a master rather than just slaves. This enables applications to scale out the number of reads and writes. However, this also requires that our applications generate universally unique identifiers, also known as “UUIDs”, or sometimes referring to as globally unique identifiers or “GUIDs”. Otherwise, two rows in the same table on two different servers might result in the same ID, causing a data collision during the multi-master replication process.
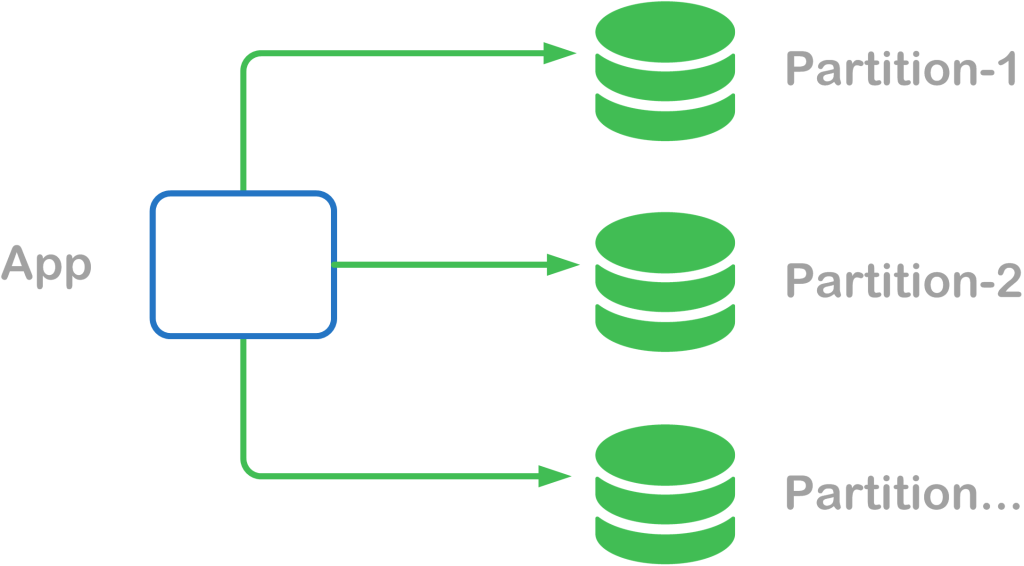
Database Scaling Pattern #3: Partitioning
Very large data sets often produce so much data that any one server cannot access or modify the data by itself without severly impacting scale and performance. This kind of problem cannot be solved through read replicas or multi-master designs. Instead, the data must be separated in some way to allow it to be easily accessible.
Horizontal partitioning, also called “sharding”, distributes data across servers. Data may be partioned to different server(s) based on a specific customer/tenant, date range, or other sharding scheme. Vertical partioning separates the data associated to a single table and groups it into frequently accessed and rarely accessed. The pattern chosen allows for the database and database cache to manage less information at once. In some cases, data patterns may be selected to move data across multiple filesystems for parallel reading and therefore increased performance.
Database Scaling Pattern #4: Connection Pooling
When an application needs to communicate with a database, it will need to make a client connection, send the requested query, and receive the results from the database. Since there is network overhead associated with establishing the client connection to the database, connections are often established by the application server initially, then the connection is reused. As you scale your application, you will want to have more connections available to service each incoming request. This technique is called connection pooling.
With connection pooling, the application server creates a pool of connections to the database, preventing the need to establish a new database connection on each incoming request.
Database Scaling Pattern #5: Connection Load Balancing
Each database vendor is designed to handle a maximum number of client connections from application servers. This means that as you scale your software, a database will be required to handle more concurrent connections from the increasing number of application servers available. To overcome this limitation while ensuring your application scales, a technique known as connecting load balancing is required.
A database load balancer supports a higher number of concurrent connections from your application servers. The balancer is then responsible for distributing the incoming database query to one of the available servers using its connection pool. This not only reduces the number of overall client connections that a database must support, it also removes the need for applications to perform connection failover to another server in the event of a database server failure. Instead, the load balancer handles this job directly.