Server Scaling Strategies
Servers are the most basic building blocks in software architecture.
They perform a variety of tasks, including:
- Static Web server
- Web application server
- Load balancer/Reverse proxy server
- API/mobile backend server
- API middleware server
In traditional software architecture, servers are expected to run for years. In a cloud native architecture, they may live for weeks, days, or perhaps even a few minutes or hours. When we view servers as temporary resources, it allows us to shift our architectures from a static view to a more dynamic view that is able to handle huge variations in workflow and scale.
While each type of server will require a different configuration to perform its job, the principles of each type of server are the same. Let’s dig into the details to better understand the server component of a Realscale architecture.
Realscale Servers Are Short-Lived (Ephemeral)
When deploying to a data center or to the public cloud using a traditional approach, servers are long-lived. These servers are considered the life blood of the product and are meant to live on for years. They must be continually updated, patched, and kept running at all costs. To scale traditional servers, more CPU, memory, and disk space is required (i.e. “vertical scaling”). An outage of one of these servers is cause for alarm. Failure to perform consistent backups means that hours, days, weeks, or even months of hard work may be lost and will take time to reconstruct (if it can be reconstructed at all).
Since servers in a Realscale architecture are considered utility resources, they may be created and terminated on demand. Rather than configuring a single long-lived server and attempting to scale it vertically, we scale horizontally by adding or removing servers as needed. This capability is often described as “elasticity.”
Taking Advantage of Server Elasticity
Elasticity is the on-demand growth or shrinkage of a resource for a specific time. In short: only what you need, only when you need it.
Elasticity, however, is about more than just CPU power. Any resource is capable of being pooled, automated, and managed may be elastic: CPUs, memory, storage, databases, network bandwidth, message brokers, deployment platforms, web applications, etc.
It is important to note that elasticity is different from scalability. Scalability is dealing with growth or shrinkage of resources over time, whereas elasticity is related to a specific period of time.
As an example, several years ago a major retailer experienced a severe shortage of servers during the Christmas season. This caused a variety of problems when taking orders online. Their need wasn’t driven from month-over-month growth of customer usage (scalability), but increased web traffic for that specific time of the year (elasticity).
While elasticity can be achieved manually or through automation scripts, most often elasticity is managed through the use of scaling groups.
Scaling Using Server Scaling Groups
Scaling groups allow servers that perform the same task to be managed together, allowing for the increase or decrease of the servers within the group based on demand capacity. These scaling groups are configured with a minimum and maximum threshold for the number of servers required. Rules are then assigned to the group to allow a group of servers to grow and shrink based on the current workload. When burst capacity is needed, more servers are added into the scaling group. As the capacity requirements diminish, servers in the group may be terminated as needed until the minimum threshold is reached.
The diagram below shows a scaling group with a minimum of 3 servers and maximum of 9 servers. The scaling group can grow and shrink as required to support the current application capacity:
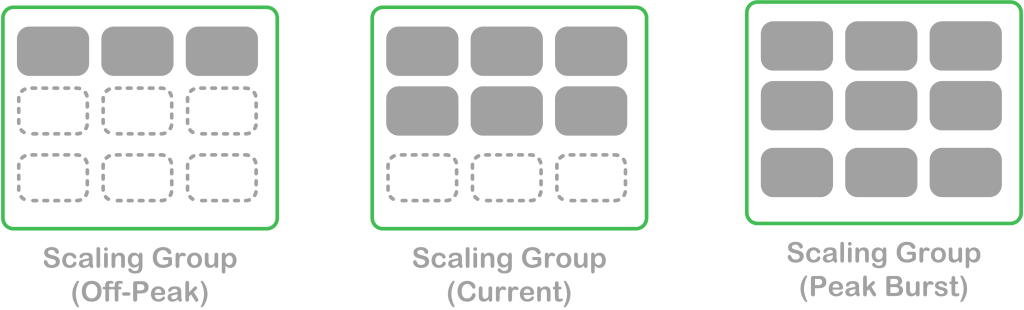
Servers in a cloud native architecture are designed with outages in mind. Realscale servers utilize shared network storage to persist important data after the server is terminated, or utilize a highly-available data replication scheme to prevent data loss. However, the loss of one or more servers doesn’t impact the system, other than temporarily reducing the total overall processing capacity until new servers come online.
It is important to note that because servers may be added and removed from scaling groups at any time, there are a number of changes to server management over a traditional approach. This includes how we deploy, perform backup/restoration, and handle our data management processes.
Distributing Requests Across Servers Using Load Balancing
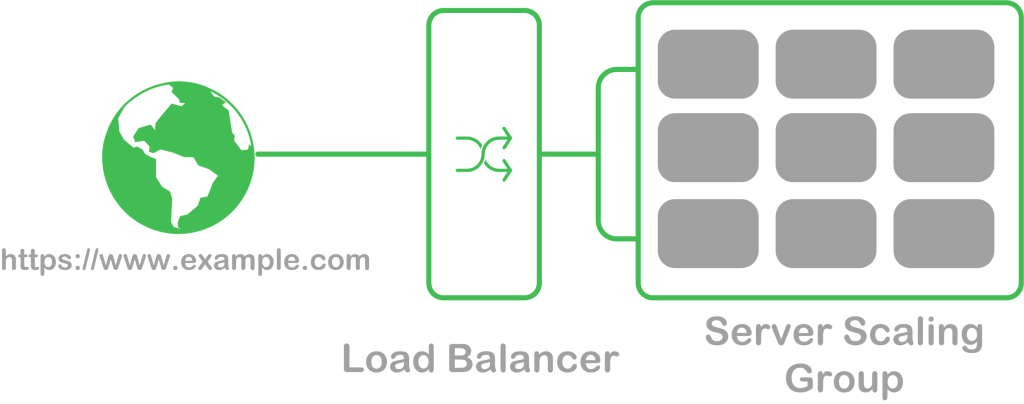
Most often, a load balancer is placed in front of the group to route requests to one of the servers within the group. Load balancers round-robin requests to each server in the group or assign requests to a server based on its current workload. One or more public domain names are assigned to a load balancer, allowing it to respond to all requests for a specific server (e.g. https://www.example.com).
In the diagram below, a load balancer is used to distribute incoming HTTP requests to one of a number of servers within a server scaling group:
How Elasticity Impacts Server Configuration and Deployment
With a traditional server architecture, the servers we manage are well-known. Often, they are servers that we have managed for years and have a known DNS name and IP address. Our deployment scripts push our code releases and perform other server management tasks for these specific servers.
Realscale architectures must have configuration and deployment scripts that are resilient to infrastructure change. The number of servers, along with their server DNS names and IP addresses will vary. We also need new servers added to a scaling group to be configured the exact same way – including all server configuration, the same installed packages/versions, the exact code release, and the same application-specific settings. In a cloud native architecture, we no longer write scripts that push our deployment and configuration tasks to specific servers. Instead, the servers need to pull their code and configuration from a centralized location.
How Elasticity Impacts Server Backup and Restore
Traditional server architectures require backups to include most or all of the filesystem, including configuration files, installed packages, assets, code, and other files. Realscale architectures strive to automate the creation of new server images and server configuration. Backup and restore processes for an entire server instance is a rare process.
Instead, the infrastructure is managed just like an application codebase: under version control. Changes to server configurations can be deployed or reverted as needed. Only assets that cannot be easily reconstructed are archived: database snapshots, user uploads, and log files. This doesn’t mean that a disaster recovery plan, along with a great backup and restore process isn’t necessary. It just means that the process is focused more on generated data than filesystems from specific servers since everything can be recreated by executing these automation scripts.
A Note on Dealing with Specialized, One-Off Servers
So far, we have mostly discussed web and API servers that are grouped into a scaling group. But, what about specialized servers where a single instance is all that is needed? These servers should be follow the same patterns, including scaling groups, server management, application deployment, and backup/restore processes.
The only difference is that they will exist within a scaling group with a minimum of 1, maximum of 1 instance. This prevents multiple instances of the same server from existing at the same time. When the instance terminates unexpectedly, the scaling group will start a new server instance to replace it. This requires the same deployment processes in place as for elastic scaling groups. We will also utilize shared network storage to ensure that there is no data loss in the case of server failure.