Cloud Storage Scaling Strategies
Nearly every application has a requirement to store data of some kind: uploaded files, images, videos, etc.
Traditional architectures utilize local storage, perhaps shared with other servers. Since traditional servers are designed to live for a long period of time, this may be an acceptable solution. However, for a cloud native architecture, servers are created and destroyed frequently. This places a new requirement of shared storage beyond the individual server. Let’s examine the options available for Realscale architectures.
Types of Cloud Storage Solutions
Local Ephemeral Storage
Local server storage is still an option for cloud native architectures. However, local storage should be considered ephemeral (i.e. not long lasting). Instead, local storage must be used only for storing temporarily files and logs before they are moved to long-term storage. Any configuration files should be obtained from a source not originating from the server, since the server may be destroyed at any time. Databases using local ephemeral storage should either be replicated to other servers immediately, or applications should be designed to withstand data loss due to server shutdown.
Network Filesystem
Similar to Network Attached Storage (NAS), a shared filesystem allows one or more servers to connect to the same filesystem and read/write files. Often, shared filesystems are exported using one or more network file system protocols: NFS, SMB/CIFS, or AFP. Depending on the specific service offered, some shared filesystem services do not allow storage capacity to be added after the pre-allocated storage has been reached.
Servers using a shared filesystem utilize the network protocol for reading and writing files, allowing the remote server to perform the block-level input/output directly. As a result, shared filesystems are not recommended for solutions that require direct block-level device I/O access (e.g. high performance data stores).
Access to the shared filesystem is limited to the local network.
Network Device/Block Storage
Similar to a Storage Area Network (SAN), network block storage is a block-level device (i.e. tracks and sectors) offered over the network. To the server, a block storage device looks like any other kind of storage media and may be mounted, formatted with any kind of filesystem, and even combined with other block storage devices for redundancy or performance (e.g. RAID 0, 1, 5, 10, 50).
Block storage is often used for high performance data stores, where direct I/O access is needed over filesystem access. Depending on the specific service offered, some block storage services do not allow storage capacity to be added after the pre-allocated storage has been reached.
Access to block storage is limited to the local network.
Object Storage
Object storage lives above the block or filesystem, allowing for the storage of data and associated meta data. Often, object stores will use block or filesystem storage underneath, but those details are not exposed to the client. Instead, an application programming interface (API) is used to access the objects. Many object storage services offer a REST-based API, making it easy to read, write, update, and delete objects from any application without the concerns of filesystems or direct block-level I/O. Object stores often provide high availability and redundancy in a transparent way.
Object storage is often available from any location, including local and remote networks (assuming proper credentials are provided for read and/or write access). Some object storage services offer sharing public files directly to browsers over HTTP, allowing entire websites to be stored and served without requiring a dedicated web server.
Example 1: Object vs. Local Storage vs. Network Storage
In the diagram below, several files are stored across object storage, local server storage, and a network filesystem:
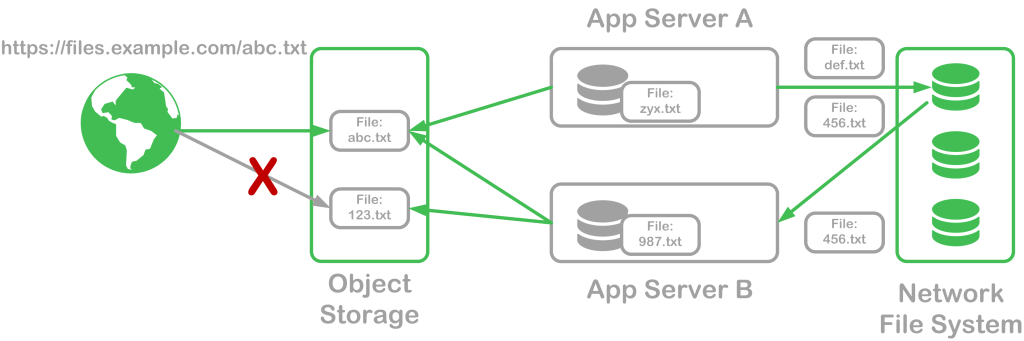
Each of the files have different access rules:
- abc.txt – available from anywhere, including a desktop computer and both app servers
- 123.txt – available only to the app servers, as security permissions prevent public access
- zyx.txt and 987.txt – available only from the local app server, are not shared between servers or to a desktop computer. These files will be lost when the app server is destroyed
- def.txt and 456.txt – available from any server that has mounted the network filesystem and has the permission to do so, but cannot be accessed from anywhere
Example 2: Local Storage vs. Network Block Storage
In the following diagram, database server A and B are running MySQL. Each server has the option of storing its data locally, but losing the data if the server is every destroyed. As a second option, server A could use a network block device, configured for high availability and performance using RAID-10, to store the MySQL data. If server A is lost, server B can mount the same block device and recover the data.

How to Select a Scalable Cloud Storage Strategy
With so many choices available, how do you decide what kind of storage strategy to use for your cloud native application? Here are some guidelines to help you:
- Use Object Storage for storing and reading files from anywhere, even outside the local network
- Use Block Storage for high performance I/O, such as databases, that need direct read/write access to a storage device
- Use Shared Filesystem for local network storage of files that need to appear as if they are local to the server, or when you need the hierarchical nature of a filesystem rather than the more flat structure of Object Storage
- Use Local Storage when temporary local storage is required, when building your own shared filesystem that is resilient to individual server outages, or for databases that shard data across multiple servers (e.g. Cassandra). When using local storage, try to provision SSD-based local storage for faster I/O performance